Pattern and object recognition
adapted from various sources (linked below)
The world that we perceive is complex. For example, a visual scene typically has many overlapping sufaces that vary in shape, color, depth, and change based on the viewer’s perspective. Despite this, we perceive our visual world as composed of multiple distinct objects with particular shapes that we infer from incomplete information. The processes of pattern recognition and object recognition refer to our ability to take sensory input and turn it into a meaningful perceptual interpretation.

Psychologists often distinguish between top-down and bottom-up approaches to information-processing. In top-down approaches, knowledge or expectations are used to guide processing. That is, these accounts suggest perception results from hypotheses about sensory information based on prior knowledge (e.g., Gregory, 1970). Bottom-up (or data driven) approaches, however, are more like the structuralist approach, piecing together data to reach the bigger picture. For example, Gibson’s (1966) theory of direct perception claims that the real world provides sufficient contextual information for our visual systems to directly perceive what is there, unmediated by the influence of higher cognitive processes. Gibson developed the notion of affordances, referring to those aspects of objects or environments that allow an individual to perform an action. Gibson’s emphasis on the match between individual and environment led him to refer to his approach as ecological. Most psychologists now would argue that both bottom-up and top-down processes are involved in perception.
Bottom-up theories
Template Matching:
One way for people to recognize objects in their environment would be for them to compare their representations of those objects with templates stored in memory. For example, if I can achieve a match between the large red object I see in the street and my stored representation of a London bus, then I recognize a London bus. However, one difficulty for this theory is illustrated in the figure to the right.
{kind=link}

Here, we have no problem differentiating the middle letters in each word (H and A), even though they are identical (so presumably would activate the same template). A second problem is that we continue to recognize most objects regardless of what perspective we see them from (e.g. from the front, side, back, bottom, top, etc.). This would suggest we have a nearly infinite store of templates, which seems unlikely.
Feature Analysis:
Feature-matching theories propose that we decompose visual patterns into a set of critical features, which we then try to match against features stored in memory. For example, in memory I have stored the information that the letter “Z” comprises two horizontal lines, one oblique line, and two acute angles, whereas the letter “Y” has one vertical line, two oblique lines, and one acute angle. I have similar stored knowledge about other letters of the alphabet. When I am presented with a letter of the alphabet, the process of recognition involves identifying the types of lines and angles and comparing these to stored information about all letters of the alphabet. If presented with a “Z”, as long as I can identify the features then I should recognize it as a “Z”, because no other letter of the alphabet shares this combination of features.
The best known model of this kind is Selfridge’s (1959) Pandemonium model, where information is processed through various stages by what Selfridge described as “mental demons,” who shout out loud as they attempt to identify patterns in the stimuli. These pattern demons are at the lowest level of perception so after they are able to identify patterns, computational demons further analyze features to match to templates such as straight or curved lines. Finally at the highest level of discrimination, cognitive demons which allow stimuli to be categorized in terms of context and other higher order classifications, and the decisions demon decides among all the demons shouting about what the stimuli is which while be selected for interpretation.
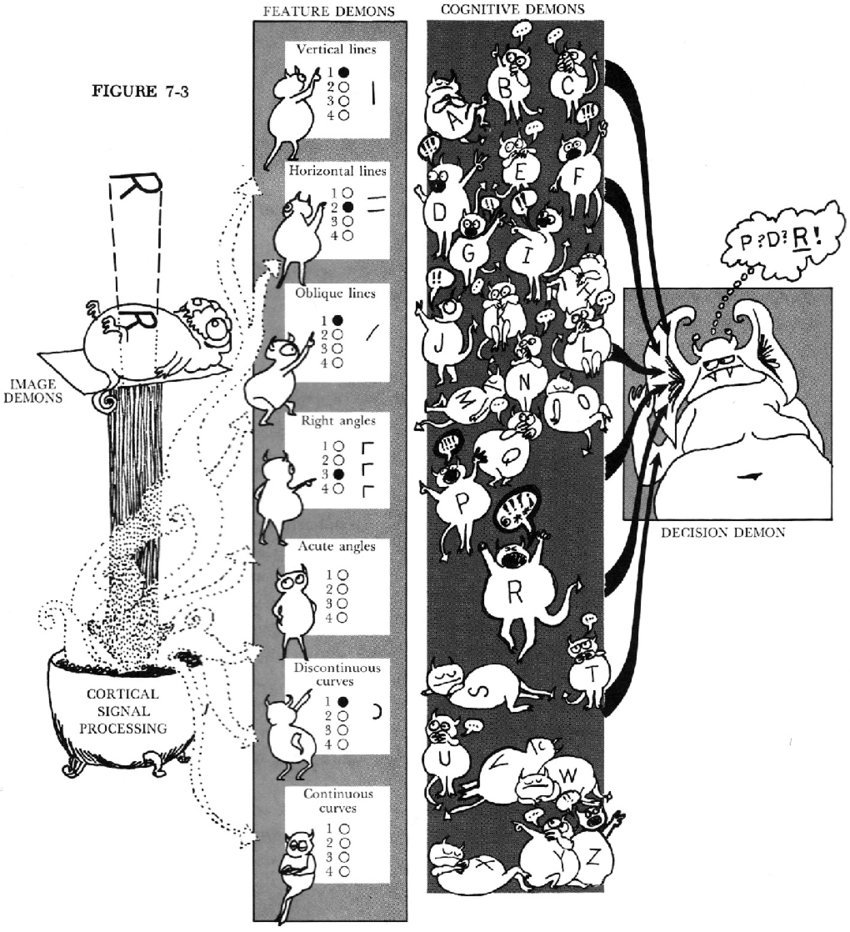
Although layers of shouting demons may seem a bit unscientific, the model actually incorporates several ideas that are important for pattern recognition. First, this model is a feature detection model that incorporates higher levels of processing as the information is processed in time. Second, the model incorporates ideas of parallel processing suggesting many different levels of analysis can happen to some extent at the same time. Third, the model suggests that perception is essentially a series of problem solving procedures, where we take bits of information and piece it all together to create something we are able to recognize and classify as something meaningful.
One source of evidence for feature matching comes from Hubel and Wiesel’s (Nobel Prize winning) finding that the visual cortex of cats contains neurons that only respond to specific features (e.g. one type of neuron might fire when a vertical line is presented, another type of neuron might fire if a horizontal line moving in a particular direction is shown).
However, one difficulty for feature-matching theory comes from the fact that we are normally able to read slanted handwriting that does not seem to conform to the feature description given above. For example, if I write a letter “L” in a slanted fashion, I cannot match this to a stored description that states that L must have a vertical line. Another difficulty arises from trying to generalize the theory to the natural objects that we encounter in our environment (e.g., what are the features of the terrapins in the first figure on this page?).
Top-down theories
The Gestalt principles of perception
In the early part of the 20th century, Max Wertheimer (1912) published a paper demonstrating that individuals perceived motion in rapidly flickering static images (an insight that came to him as he used a child’s toy tachistoscope). Wertheimer and his colleagues argued that perception involved more than simply combining sensory stimuli. This belief led to a new movement within the field of psychology known as Gestalt psychology. The word gestalt literally means “form” or “pattern,” but its use reflects the idea that the whole is different from the sum of its parts. In other words, the brain creates a perception that is more than simply the sum of available sensory inputs, and it does so in predictable ways. Gestalt psychologists translated these predictable ways into principles by which we organize sensory information. As a result, Gestalt psychology has been extremely influential in the area of sensation and perception (Rock & Palmer, 1990; Wagemans et al., 2012).
Gestalt perspectives in psychology represent investigations into ambiguous stimuli to determine where and how these ambiguities are being resolved by the brain. They also aim to understanding sensory and perception as processing information as groups or wholes instead of constructed wholes from many small parts.

One Gestalt principle is the figure-ground relationship. According to this principle, we tend to segment our visual world into figure and ground. Figure is the object or person that is the focus of the visual field, while the ground is the background. As the figure to the right shows, our perception can vary tremendously, depending on what is perceived as figure and what is perceived as ground. Presumably, our ability to interpret sensory information depends on what we label as figure and what we label as ground in any particular case.
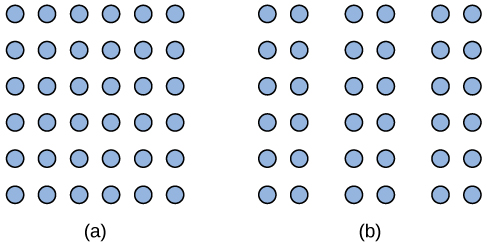
Another Gestalt principle for organizing sensory stimuli into meaningful perception is proximity. This principle asserts that things that are close to one another tend to be grouped together, as the figure below illustrates.
How we read something provides another illustration of the proximity concept. For example, we read this sentence like this, notl iket hiso rt hat. We group the letters of a given word together because there are no spaces between the letters, and we perceive words because there are spaces between each word. Here are some more examples: Cany oum akes enseo ft hiss entence? What doth es e wor dsmea n?

We might also use the principle of similarity to group things in our visual fields. According to this principle, things that are alike tend to be grouped together (figure at left). For example, when watching a football game, we tend to group individuals based on the colors of their uniforms. When watching an offensive drive, we can get a sense of the two teams simply by grouping along this dimension.
Two additional Gestalt principles are the law of continuity (or good continuation) and closure. The law of continuity suggests that we are more likely to perceive continuous, smooth flowing lines rather than jagged, broken lines (figure to right). The principle of closure states that we organize our perceptions into complete objects rather than as a series of parts (figure below).

According to Gestalt theorists, pattern perception, or our ability to discriminate among different figures and shapes, occurs by following the principles described above. You probably feel fairly certain that your perception accurately matches the real world, but this is not always the case. Our perceptions are based on perceptual hypotheses: educated guesses that we make while interpreting sensory information. These hypotheses are informed by a number of factors, including our personalities, experiences, and expectations.
One criticsm of the Gestalt approach to perception is that it is largely descriptive instead of offering explanations or models of how perception occurs. Another top-down approach that is somewhat more mechanistic is called Recognition by components.
Recognition by components
The recognition-by-components theory (Biderman, 1987) is a top-down process proposed by Biederman (1987) to explain object recognition. According to this theory, we are able to recognize objects by separating them into geons (the object’s main component parts). Biederman suggested that geons are based on basic 3-dimensional shapes (cylinders, cones, etc.) that can be assembled in various arrangements to form a virtually unlimited number of objects.
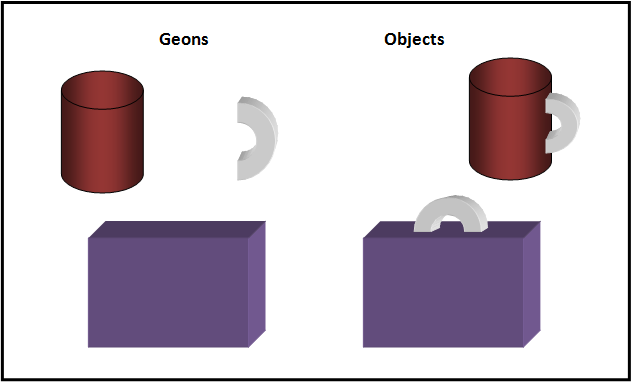
The recognition-by-components theory suggests that there are a small set of geons which are combined to create the objects we see in day-to-day life. For example, when looking at a mug we break it down into two components – “cylinder” and “handle”, and an ice cream cone could be broken down into a sphere located above a cone. This also works for more complex objects, which in turn are made up of a larger number of geons. Perceived geons are then compared with objects in our stored memory to identify what it is we are looking at. The theory proposes that when we view objects we look for two important components.
- Edges – This enables us to maintain the same perception of the object regardless of viewing orientation.
- Concavities – The area where two edges meet. These enable us to observe the separation between two or more geons.
A defining feature of the recognition-by-components theory is that it enables us to recognize objects regardless of viewing angle; this is known as viewpoint invariance. This results from the invariant edge properties of geons (Biederman, 2000). The invariant edge properties are:
- Curvature (various points of a curve)
- Parallel lines (two or more points which follow the same direction)
- Co-termination (the point at which two points meet and therefore cease to continue)
- Symmetry and asymmetry
- Co-linearity (points branching from a common line)
Our knowledge of these properties means that when viewing an object or geon, we can perceive it from almost any angle. For example, when viewing a brick we will be able to see horizontal sets of parallel lines and vertical ones, and when considering where these points meet (co-termination) we are able to perceive the object.
A dark side of top-down perception: Bias, prejudice, and cultural factors
In this chapter, you have learned that perception is a complex process. Built from sensations, but influenced by our own experiences, biases, prejudices, and cultures, perceptions can be very different from person to person. These top-down aspects of perception can have a dark side: Research suggests that implicit racial prejudice and stereotypes affect perception. For instance, several studies have demonstrated that non-Black participants identify weapons faster and are more likely to identify non-weapons as weapons when the image of the weapon is paired with the image of a Black person (e.g., Payne, Shimizu, & Jacoby, 2005). Similarly, White individuals’ decisions to shoot an armed target in a video game is made more quickly when the target is Black (Correll, Park, Judd, & Wittenbrink, 2002).
Conclusion
We somehow generate a perception of a world full of distinct objects despite typically having sensory information from only partial aspects of multiple objects. Bottom-up approaches suggest different ways to extract meaning from sensory information, whereas top-down theories emphasize the role of hypotheses and prior knowledge in our perception. Both types of approaches emphasize that our perception is not infallible, and most researchers today assume some combination of bottom-up and top-down processes guiding pattern and object recognition.
References
- Biederman, I. (1987). Recognition-by-components: A theory of human image understanding. Psychological Review. 94 (2): 115–47.
- Biederman, I. (2000). Recognizing depth-rotated objects: A review of recent research and theory. Spatial Vision, 13, 241–253.
- Correll, J., Park, B., Judd, C. M., & Wittenbrink, B. (2002). The police officer’s dilemma: Using ethnicity to disambiguate potentially threatening individuals. Journal of Personality and Social Psychology, 83(6), 1314.
- Gibson, J. J. (1966).The Senses Considered as Perceptual Systems. Boston: Houghton Mifflin.
- Gregory, R. (1970). The Intelligent Eye. New York: McGraw-Hill
- Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of Physiology, 160(1), 106-154.
- Lindsay, P. H., & Norman, D. A. (1972). An Introduction to Psychology. New York, NY: Academic Press
- Payne, B. K., Shimizu, Y., & Jacoby, L. L. (2005). Mental control and visual illusions: Toward explaining race-biased weapon misidentifications. Journal of Experimental Social Psychology, 41(1), 36-47.
- Rock, I., & Palmer, S. (1990). The legacy of Gestalt psychology. Scientific American, 263(6), 84-91.
- Selfridge, O.G. (1959) Pandemonium: a paradigm for learning. In Proceedings of the Symposium on Mechanisation of Thought Processes (Blake, D.V. and Uttley, A.M., eds), pp. 511–529, H.M. Stationary Office
- Solso, R., and McCarthy, J.E. (1981). Prototype formation of faces: A case of pseudomemory. British Journal of Psychology, 72, 499-503.
- Wagemans, J., Elder, J. H., Kubovy, M., Palmer, S. E., Peterson, M. A., Singh, M., & von der Heydt, R. (2012). A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure–ground organization. Psychological bulletin, 138(6), 1172.
- Wertheimer M. (1912). Experimentelle Studien über das Sehen von Bewegung. Zeitschrift für Psychologie, 61:161–265. (Translated extract reprinted as “Experimental studies on the seeing of motion”. In T. Shipley (Ed.), (1961). Classics in psychology (pp. 1032–1089). New York, NY: Philosophical Library.)
Adapted from Wikipedia and cognitivepsychology.wikidot.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License and from The Gestalt Principles of Perception by Kathryn Dumper, William Jenkins, Arlene Lacombe, Marilyn Lovett, and Marion Perimutter under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.